
9 MIN READ
Matthew Powers | 11 October 2022
Version 2.0 of the Delta Lake storage framework was recently released, adding multiple features that make it even easier to manage your data lake. Delta Lake is an open project that’s committed to the Linux Foundation’s desire to unlock the value of shared technology. It has shown strong growth in popularity since its initial 1.0 release, as is evidenced by the number of monthly downloads (presented in the Data + AI Summit 2022 Day 1 keynote by Michael Armbrust).

Source: Michael Armbrust Keynote and Diving into Delta Lake 2.0 by TD & Denny Lee
This post explains the types of workloads to which Delta Lake is well suited and looks at why organizations are increasingly attracted to open file formats for storing their data. It also discusses some of the specific features that were added in Delta Lake 2.0 that make it an even more attractive option for the open source community.
Why data lakes?
Technological improvements have enabled organizations to collect more and more data over the years. Data lakes emerged as an alternative to databases to help organizations scale and store their massive datasets while managing costs. They are flexible and especially well suited to dynamic advanced analytics, machine learning, and AI.
Data lakes originally consisted of files in cloud-based storage systems in the CSV, JSON, or Parquet file formats. They have several advantages compared to databases and data warehouses. For example:
- Using open file formats prevents vendor lock-in.
- Storing files in the cloud with open formats is usually cheaper than using proprietary data services.
- Data lakes are generally more scalable (it’s no problem to write 50 terabytes to a data lake every day, but a database might not be able to handle this volume).
If you’d like to learn more about the advantages of data lakes, see Chapter 9 of Learning Spark, 2nd edition.
However, data lakes don’t come without a cost, and they do have some notable downsides:
- They don’t support transactions, so can easily be corrupted.
- They don’t support indexes, so queries can be slow.
- Some common data operations aren’t easy to perform (like dropping a column).
Why Delta Lake?
Delta Lake was designed to give users the best of both worlds: the usability of a database with the scalability of a data lake. Delta Lake is an abstraction built on top of the open source Parquet file format. It adds a transaction log, which allows data lake users to have access to features that are common in databases.
Here are some of the nice features Delta Lake offers:
- ACID transactions: Protect your data with serializability, the strongest level of isolation
- Scalable metadata: Handle petabyte-scale tables with billions of partitions and files with ease
- Time travel: Access/revert to earlier versions of data for audits or rollbacks
- Open source: Community driven, open standards, open protocol, open discussions
- Unified batch/streaming: Exactly once semantics ingestion to backfill to interactive queries
- Schema evolution/enforcement: Prevent bad data from causing data corruption
- Audit history: Log all change details, providing a full audit trail
- DML operations: SQL, Python, Scala, and Java APIs to merge, update, and delete datasets
- And much more!
From a usability and performance perspective, Delta Lakes are almost always better than plain vanilla data lakes. Delta Lakes have tons of built-in features that professional practitioners need when managing their datasets.
Let’s look at why organizations also like the open nature of Delta Lake.
The future of data is open
There has already been a huge move toward open source file formats, and the trend is clear: more data will be stored in these formats in the future. The reasons are obvious: open source file formats are battle-tested, can handle massive datasets, and importantly don’t subject organizations to vendor lock-in. Data professionals want data formats that are interoperable so they can easily switch from one query execution platform to another. They also want to use file formats that don’t tie them to a specific vendor. Some data professionals even want to be able to contribute pull requests to improve the data formats that they use for their day jobs.
Delta Lake is riding this wave: it’s an open source data format that’s growing rapidly in popularity because of the market demand for performant, reliable, open data storage. The 2.0 release will only aid this growth, adding new features that data professionals will quickly come to rely on.
New features in Delta Lake 2.0
The following image summarizes the features supported by Delta Lake as of the 2.0 release:

Let’s take a closer look at some of these new features.
Data skipping via column statistics
As of version 1.2, Delta Lake gathers file statistics in the transaction log. Those statistics include the row count and the min/max values for each column in the file. Delta Lake can intelligently leverage these file statistics when running queries to read less data into the cluster, which speeds up execution time.
Suppose you have a dataset with created_at, user_id, and first_name columns. You’d like to fetch all rows where created_at=2022-01-14 and first_name=bob. Further suppose that your data is stored in 10,000 Parquet files, but only 3 of those files contain relevant data.
Rather than read all 10,000 files into the cluster and perform a large filtering operation, it’s far more efficient to first use the min/max column values in the file metadata to determine which files you need to scan (in this case, just 3 of them), and then perform the filtering operation.

The ability to entirely skip irrelevant files is the source of one of the biggest performance gains when querying Delta Lakes. Because Delta Lake stores file metadata in the transaction log, it can rapidly identify the files with relevant data for a given query.
Z-Order indexing
The best way to make data skipping via column statistics more efficient is by ordering the data. If you want to order your data based on multiple columns, it’s best to Z-Order the data which was added as part of Delta Lake 2.0.
Suppose you have a data table with x, y, and surname columns, and you’re frequently filtering on the x and y columns. To increase the number of files that can be skipped when running queries, you can Z-Order the Delta Lake on those two columns. Z-Ordering the data increases the likelihood of being able to skip more non-relevant files when reading data.
How does this work? The key is that linear ordering sorts on one dimension, whereas Z-Ordering sorts on multiple dimensions. Linear ordering is therefore fine when you are only performing operations that benefit from sorting on a single dimension, but Z-Ordering is better for queries that benefit from data being sorted on multiple dimensions. The following diagram highlights the difference.
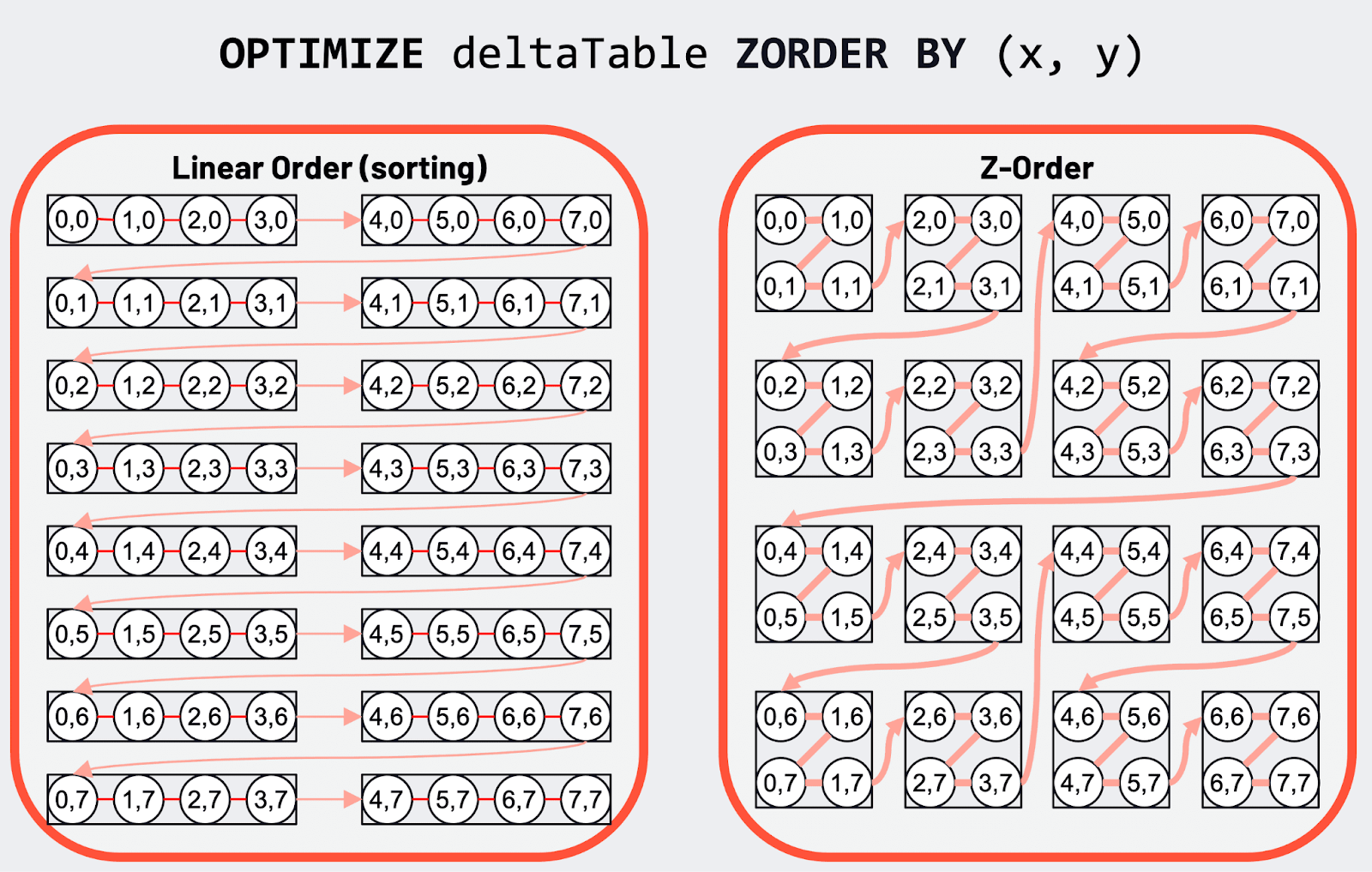
Source: Delta 2.0 Blog Post
Delta Lake 2.0’s support for Z-Ordering results in a huge performance improvement for many queries.
Delta table change data feed
Delta Lake 2.0 users can optionally enable a change data feed that lets you capture changes made to Delta Lake tables, by version. The following example will give you a better idea of how it works:
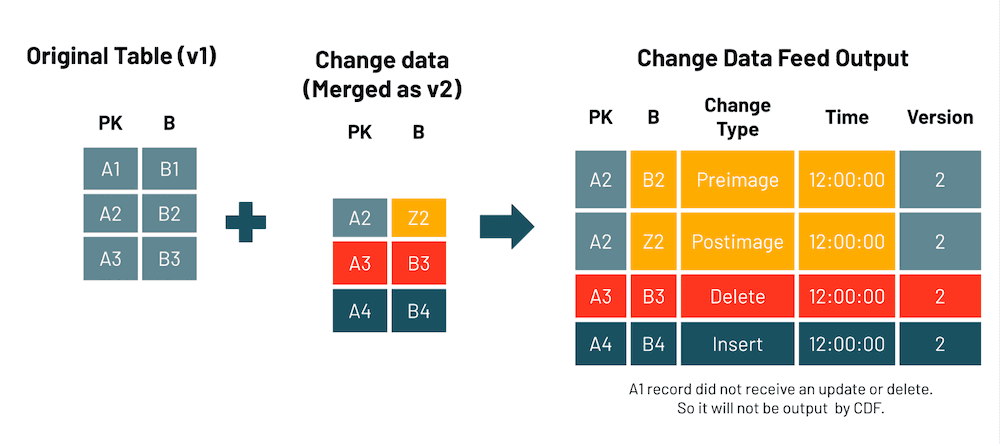
Here we have an original table that’s updated with some change data via a merge operation. Here’s what’s recorded in the change data feed output:
- Nothing is recorded for PK=A1 because it hasn’t changed.
- The change data feed shows PK=A2’s start value before and end value after the merge.
- It also shows that A3 was deleted and A4 was inserted.
The change data feed allows you to perform certain types of analysis more easily. For example, you can use the change data feed to intelligently upsert changes in downstream tables. It can also be used as an audit log.
Users of the new version of Delta Lake can simply enable the change data feed to access these great features!
Drop column support
Delta Lake 2.0 allows you to drop columns via a pure metadata operation, which is a lot faster than physically dropping columns. Physically dropping a column in a typical data lake requires a large data rewrite, which is computationally expensive. This is because Parquet files are immutable, so there is no way to drop a column by mutating an existing file. To physically drop a column, you need to read in the file, write just the columns you want to retain to a new file, and delete the original file.
In Delta Lake 2.0, you can avoid this expensive operation by simply adding an entry to the transaction log that instructs Delta Lake to ignore the column you want to drop from this point on. Delta Lake doesn’t physically delete the column from disk, it just ignores it whenever you run a query.
Adding a new entry to the Delta Lake transaction log is essentially instantaneous. Delta Lake 2.0 thus lets you drop a column in less than a second, avoiding the need for a time-consuming near-full data rewrite in cases where physically deleting the data is not required (see this blog post for more details).
The Delta Lake Connector ecosystem
Good connectors are critical for enabling the use of file formats. Data practitioners often want to mix and match different technologies when building ETL pipelines, writing out data with one data processing engine and seamlessly reading it in with another to continue their analysis with a different library ecosystem. Delta Lake’s commitment to supporting a constantly growing range of connectors makes it easy to build ETL pipelines with a variety of technologies, and engineers from an array of industries and companies have contributed to this effort by building connectors.
Delta Lake’s connector ecosystem is large and growing fast, as the following figure shows:

Delta Lake recently added connectors for Presto, Flink, and Trino, and more are on the way. The MySQL and Google Big Query connectors are coming soon!
Delta Lake contributors
The Delta Lake community is large and growing. According to the Linux Foundation Insights, the contributor strength of the Delta Lake project has increased by over 564% over the last three years, as shown in the following figure:

A contributor is “anyone who is associated with the project by means of any code activity (commits/PRs/changesets) or helping to find and resolve bugs.”
Open source projects thrive based on an active community. They’re rarely successful if they’re only built by a handful of individuals, and usually perform best if new features are added and bugs are squashed by the community.
Conclusion
The Delta Lake community welcomes new members. Feel free to join our Slack channel – the community will be happy to help you get on board! You can also follow us on Twitter or LinkedIn.
Contributions via issues and pull requests are also welcome. We’re happy to help new contributors get involved with the project and are always willing to help you with your questions.